

Eine klare und verständliche Struktur der Code-Basis ist essenziell für die Softwareentwicklung. Sie erleichtert das Verständnis, die Wartung und die Erweiterung des Codes. In diesem dritten Teil unserer Blogreihe beschäftigen wir uns mit der Analyse und Überwachung der Struktur eines Java-Projekts mit jQAssistant.
Softwarestrukturanalyse mit jQAssistant
In der Softwarearchitektur gibt es bewährte Prinzipien und Muster wie das Schichtenmodell, oder das MVC-Pattern. Diese helfen dabei, die Software in überschaubare und wartbare Einheiten zu unterteilen. Mit der Zeit besteht jedoch die Gefahr, dass diese Struktur verwässert und ungewollte Abhängigkeiten entstehen.
In diesem Artikel erfassen wir die einzelnen Komponenten unserer Anwendung, visualisieren die Abhängigkeiten und schützen sie vor ungewollten Änderungen. Die vorgestellten Regeln sind Beispiele und sollten an die spezifischen Anforderungen des Projekts angepasst werden.
Den Code zu diesem Artikel findet ihr wie gewohnt auf GitHub  .
.
Neue structure.xml
Im letzten Teil der Blog-Reihe haben wir unsere jQAssistant Regeln bereits nach Kategorien in verschiedene XML-Dateien aufgeteilt. Da wir in diesem Artikel die Struktur des Projekts analysieren, erstellen wir eine neue structure.xml im Ordner jqassistant und legen darin die Regeln für die Strukturanalyse ab.
Alle Regeln aus der structure.xml müssen nun noch in die default-Gruppe in der index.xml eingebunden werden:
<jqassistant-rules xmlns="http://schema.jqassistant.org/rule/v2.2"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://schema.jqassistant.org/rule/v2.2 https://schema.jqassistant.org/rule/jqassistant-rule-v2.2.xsd">
<group id="default">
<includeConcept refId="common:*"/>
<includeConcept refId="metrics:*"/>
<includeConcept refId="structure:*"/>
<includeConstraint refId="metrics:*"/>
<includeConstraint refId="structure:*"/>
</group>
</jqassistant-rules>
Damit die neuen Analysen zur Struktur des Projekts auch in der Dokumentation erscheinen, müssen wir noch folgende Zeile in die Datei src/ einfügen:
=== Struktur
include::jQAssistant:Rules[concepts="structure:*",leveloffset=+3]
Komponenten ermitteln
Bei der Aufteilung einer Anwendung in Komponenten kann man verschiedene Kriterien anwenden. In der Beispiel-Anwendung im dazugehörigen GitHub-Repository wurden die drei Komponenten movie, schedule und theater nach ihren fachlichen Zuständigkeiten getrennt. Jede Komponente ist intern wiederum in die technischen Komponenten web, service und persistence nach der Schichtenarchitektur unterteilt.
Diese Unterpakete der Komponenten werden im weiteren Verlauf als Subkomponenten bezeichnet. Für die weitere Analyse der Struktur der Abwendung werden wir die entsprechenden Knoten für die Packages der Komponenten und Subkomponenten in der Neo4j-Datenbank mit entsprechenden Labels anreichern. Dem Knoten für das Package com. weißen wir also das Label Component und dem Knoten für das Package com. ndas Label SubComponent zu.
Um nicht alle Komponenten und Subkomponenten in einer Cypher-Query einzeln identifizieren zu müssen, verfolgt die folgende Regel einen generischen Ansatz.
<concept id="structure:Component">
<description>
All packages under the root package of the main artifact are labeled as `Component`.
All packages under `Component` packages are labeled as `SubComponent`
</description>
<cypher><![CDATA[
MATCH
(:Main:Artifact)-[:CONTAINS]->(rootPackage:Package)-[:CONTAINS]->(component:Package)-[:CONTAINS]->(subComponent:Package)
WHERE
rootPackage.fqn = 'com.example.moviescheduler'
SET
component:Component, subComponent:SubComponent
WITH
component, collect(subComponent.name) AS UnsortedSubComponents
UNWIND
UnsortedSubComponents AS subComponentName
WITH
component, subComponentName
ORDER BY
subComponentName
RETURN
component.name AS Component, collect(subComponentName) AS SubComponents
ORDER BY
component.name
]]></cypher>
</concept>
Allen Packages, die direkt unterhalb des Root-Packages mit dem vollqualifizierten Namen com. liegen, wird das Label Component zugewiesen. Alle Packages, die unterhalb eines Component-Packages liegen, erhalten das Label SubComponent.
Um in der Ausgabe der Regel die Liste der Subkomponenten zu sortieren, wird die UNWIND-Funktion verwendet. Diese Funktion wandelt eine Liste in einzelne Elemente um, die dann sortiert und wieder in eine Liste zusammengeführt werden.
Die Ausgabe der Regel zeigt die Komponenten und ihre Subkomponenten in alphabetischer Reihenfolge an.

Abhängigkeiten zwischen Komponenten
Nachdem wir nun die Komponenten und Subkomponenten in unserem Code identifiziert haben, wollen wir die Abhängigkeiten zwischen diesen analysieren.
jQAssistant legt bereits automatisch eine :DEPENDS_ON-Beziehung zwischen allen Typen an, die voneinander abhängen. Diese Beziehung werden wir nun nutzen, um eine neue :DEPENDS_ON-Beziehung zwischen alle Komponenten und Subkomponenten zu erstellen.
Da jede Komponente oder Subkomponente gleichzeitig auch ein Package ist, werden wir aus Gründen der Einfachheit gleich eine Beziehung zwischen allen Packages erstellen. Je nach Größe des Projekts kann dieser Ansatz jedoch sehr rechenaufwändig sein. In diesem Fall empfiehlt es sich, die Abhängigkeiten zur zwischen Komponenten und Subkomponenten anzulegen.
<concept id="structure:PackageDependencies">
<description>Creates a new `DEPENDS_ON` relations between all packages</description>
<cypher><![CDATA[
MATCH
(package1:Package)-[:CONTAINS*]->(type1:Type),
(package2:Package)-[:CONTAINS*]->(type2:Type),
(type1)-[:DEPENDS_ON]->(type2)
WHERE
package1 <> package2
WITH
package1, package2, COUNT(*) AS weight
MERGE
(package1)-[dependency:DEPENDS_ON]->(package2)
SET
dependency.weight = weight
RETURN
COUNT(dependency) AS CreatedDependencies
]]></cypher>
</concept>
Die oben gezeigte Regel erstellt mit dem MERGE-Befehl auf Basis der :DEPENDS_ON-Beziehungen zwischen den Typen eine neue :DEPENDS_ON-Beziehung zwischen allen Packages. Die Anzahl der Abhängigkeiten aller Typen in den Packages wird in der Eigenschaft weight als Gewicht der Beziehung gespeichert.
Durch die Betrachtung aller CONTAINS-Beziehungen in beliebiger Tiefe, werden auch Typen aus Sub-Packages berücksichtigt. Somit werden zum Beispiel für Abhängigkeiten zwischen den Komponenten auch die Abhängigkeiten zwischen ihren jeweiligen Subkomponenten berücksichtigt.
Da Typen innerhalb eines Packages auch von anderen Typen innerhalb desselben Packages abhängen können, wird in der WHERE-Clause mit package1 <> package2 sichergestellt, dass keine Beziehung zwischen einem Package und sich selbst erstellt wird.
Visualisierung der Struktur
Architekturdiagramme sind ein gutes Mittel, um die Struktur einer Anwendung zu visualisieren und Konzepte zu vermitteln. Sie sollten in keiner Dokumentation fehlen. Doch wie aktuell sind diese Diagramme, die oft in der Anfangsphase eines Projekts erstellt werden? Wie oft werden sie aktualisiert und wie oft werden sie mit dem tatsächlichen Code abgeglichen?
jQAssistant kann hierbei unterstützen und erlaubt mithilfe des PlantUML-Report-Plug-ins die Erstellung von Diagrammen aus den Daten der Neo4j-Datenbank, die dann automatisch in die Dokumentation eingebunden werden können.
Das PlantUML-Report-Plug-in unterstützt die drei Diagrammtypen Komponentendiagramm, Klassendiagramm und Sequenzdiagramm.
Für die Visualisierung unserer zuvor ermittelten Komponenten eignet sich am besten das Komponentendiagramm, weswegen wir uns in diesem Artikel darauf beschränken werden.
Die Erstellung der anderen Diagrammtypen ist jedoch ähnlich, aus meiner Sicht jedoch nur mit einem konkreten Fokus sinnvoll. Ein Klassendiagramm aller Klassen einer Anwendung ist oft zu groß und unübersichtlich, um einen Mehrwert zu bieten. Beim Fokus auf bestimmte Code-Teile oder Konzepte kann ein Klassendiagramm jedoch sehr hilfreich sein. Die Idee eines Sequenzdiagramms aus den Daten einer Anwendung ist interessant, in der aktuellen Version des PlantUML-Report-Plug-ins entspricht das generierte Sequenzdiagramm jedoch nicht der gewohnten Form. Vielleicht werde ich hierzu in einem späteren Artikel noch einmal was schreiben.
Konzentrieren wir uns also auf die Erstellung von Komponentendiagrammen.
Visualisierung der Komponenten
Als Erstes erstellen wir ein Diagramm, das die Komponenten und ihre Abhängigkeiten untereinander darstellt. Dazu erstellen wir eine neue Regel in der structure.xml:
<concept id="structure:ComponentDependencies">
<requiresConcept refId="structure:Component"/>
<requiresConcept refId="structure:PackageDependencies"/>
<description>Shows the dependencies between components.</description>
<cypher><![CDATA[
MATCH
(component1:Component)-[dependency:DEPENDS_ON]->(component2:Component)
RETURN
component1, component2, dependency
]]></cypher>
<report type="plantuml-component-diagram"/>
</concept>
Mithilfe des <report>-Tags wird das PlantUML-Report-Plug-in angewiesen, ein Komponentendiagramm zu erstellen, welches standardmäßig als .svg-Datei im Ordner target/generated-docs abgelegt und in die Asciidoc-Dokumentation eingebunden wird.

Die Zahl an den Pfaden gibt die Anzahl der Abhängigkeiten zwischen den Komponenten an.
Visualisierung der Subkomponenten
Um noch mehr Einblick in die Struktur der Anwendung zu bekommen, können wir auch die Subkomponenten in das Diagramm einbeziehen.
<concept id="structure:SubComponentDependencies">
<requiresConcept refId="structure:Component"/>
<requiresConcept refId="structure:PackageDependencies"/>
<description>Shows components and their subcomponents with their dependencies.</description>
<cypher><![CDATA[
MATCH
(component:Component)-[:CONTAINS]->(subComponent:SubComponent)
OPTIONAL MATCH
(subComponent)-[dependency:DEPENDS_ON]->(:SubComponent)
RETURN
{
role : "graph",
parent : component,
nodes : subComponent,
relationships: dependency
}
]]></cypher>
<report type="plantuml-component-diagram"/>
</concept>
Durch die Angabe des parent-Attributs im RETURN-Statement zeichnet das PlantUML-Report-Plug-in Subkomponenten innerhalb ihrer Komponenten im Diagramm. Die nodes-Eigenschaft enthält die Subkomponenten und die relationships-Eigenschaft die Abhängigkeiten zwischen den Subkomponenten.

Validierung der Struktur
Die erzeugten Diagramme können ein erster Anhaltspunkt sein, um die Struktur der Anwendung zu verstehen und die Basis für weitere Analysen und Verbesserungen sein. Doch wie können wir sicherstellen, dass die geplante Struktur auch eingehalten wird und bei der täglichen Arbeit keine ungewollten Abhängigkeiten entstehen?
Spezifische Regeln
Eine mögliche Lösung kann die Definition von projektspezifischen Regeln sein, die die Struktur der Anwendung überwachen. Bezogen auf unser Beispielprojekt in GitHub könnte eine mögliche Regel sein, dass es keine direkte Abhängigkeit von der Web-Schicht zur Persistence-Schicht in den einzelnen Komponenten geben darf.
<constraint id="structure:NoDirectDependencyFromWebToPersistence">
<requiresConcept refId="structure:Component"/>
<requiresConcept refId="structure:PackageDependencies"/>
<description>There must be no direct dependency from the web layer to the persistence layer in any component</description>
<cypher><![CDATA[
MATCH
(web:SubComponent)-[:DEPENDS_ON]->(persistence:SubComponent)
WHERE
web.name = 'web' AND persistence.name = 'persistence'
RETURN
web.fqn, persistence.fqn;
]]></cypher>
</constraint>
Sobald die gezeigte Constraint-Regel ein Ergebnis zurückgibt, wird ein Fehler protokolliert und der Build-Prozess abgebrochen.
Wie oben schon erwähnt, sind solche Regeln sehr projekt- und teamabhängig. Die gezeigte Regel ist nur ein Beispiel und sollte auf die spezifischen Anforderungen des eigenen Projekts angepasst werden.
Instabile Komponenten
Als Alternative zu spezifischen Regeln schauen wir uns noch einen Ansatz für eine allgemeinere Regel an.
Viele Architekturmuster wie die Schichtenarchitektur oder die Zwiebelarchitektur verfolgen das Ziel, bestimmte Code-Teile vor ungewollten Änderungen schützen. Die Persistence-Schicht sollte beispielsweise nicht angefasst werden müssen, nur weil sich die Struktur der API in der Web-Schicht ändert. Oder das Domain-Modell sollte nicht angepasst werden müssen, nur weil sich die Datenbank ändert.
Die verschiedenen Modelle erreichen diese Trennung durch die Definition von Abhängigkeiten und deren Richtung zwischen den verschiedenen Teilen.
Verallgemeinert kann man also definieren, dass eine stabile Komponente einer Anwendung nicht von einer instabilen Komponente abhängen sollte. Robert C. Martin nennt dies das „Stable Dependencies Principle“. ([1] Kapitel: 14, The Stable Dependencies Principle)
Im Fall unserer Beispiel-Anwendung betrachten wir die Ebene der Subkomponenten, welche alle der Schichtenarchitektur folgen. Die folgenden Regeln lassen sich jedoch auch ohne viel Aufwand auf andere Ebenen der Anwendung anpassen.
Zur Ermittlung der Instabilität einer Subkomponente erfassen wir zunächst die Anzahl aller eingehenden Abhängigkeiten und speichern diese in einer neuen Eigenschaft ca (Afferent Coupling) ab.
<concept id="structure:AfferentCouplingOfSubComponent">
<requiresConcept refId="structure:Component"/>
<requiresConcept refId="structure:PackageDependencies"/>
<description>Set a new property `ca` for each SubComponent which holds the sum of all incoming dependencies from other SubComponents under the same Component</description>
<cypher><![CDATA[
MATCH
(component:Component)-[:CONTAINS]->(subComponent:SubComponent)
OPTIONAL MATCH
(subComponent)<-[dependency:DEPENDS_ON]-(:SubComponent)<-[:CONTAINS]-(component)
WITH
component, subComponent, sum(dependency.weight) AS afferentCouplings
SET
subComponent.ca = afferentCouplings
RETURN
component.name AS Component, subComponent.name AS SubComponent, afferentCouplings AS AfferentCouplings
ORDER BY
Component DESC, SubComponent DESC
]]></cypher>
</concept>
Und anschließend die Anzahl aller ausgehenden Abhängigkeiten, welche in einer neuen Eigenschaft ce (Efferent Coupling) gespeichert wird.
<concept id="structure:EfferentCouplingOfSubComponent">
<requiresConcept refId="structure:Component"/>
<requiresConcept refId="structure:PackageDependencies"/>
<description>Set a new property `ce` for each SubComponent which holds the sum of all outgoing dependencies from other SubComponents under the same Component</description>
<cypher><![CDATA[
MATCH
(component:Component)-[:CONTAINS]->(subComponent:SubComponent)
OPTIONAL MATCH
(subComponent)-[dependency:DEPENDS_ON]->(:SubComponent)<-[:CONTAINS]-(component)
WITH
component, subComponent, sum(dependency.weight) AS efferentCouplings
SET
subComponent.ce = efferentCouplings
RETURN
component.name AS Component, subComponent.name AS SubComponent, efferentCouplings AS EfferentCouplings
ORDER BY
Component DESC, SubComponent DESC
]]></cypher>
</concept>
Wer mehr über Afferente und Efferente Kopplung erfahren möchte, dem empfehle ich diesen Artikel . Wir werden uns im Weiteren auf die Berechnung der Instabilität unserer Subkomponenten konzentrieren.
Die folgende Regel speichert die Instabilität einer Subkomponente in einer neuen Eigenschaft instability ab. Die Instabilität einer Subkomponente wird als Quotient aus der Anzahl der ausgehenden Abhängigkeiten und der Summe der eingehenden und ausgehenden Abhängigkeiten berechnet. Eine Subkomponente mit einer Instabilität von 0 ist maximal stabil, da sie von keiner anderen Subkomponente abhängt. Eine Subkomponente mit einer Instabilität von 1 ist maximal instabil, da sie nur Abhängigkeiten zu anderen Subkomponenten hat und niemand von ihr abhängt.
<concept id="structure:InstabilityOfSubComponent">
<requiresConcept refId="structure:AfferentCouplingOfComponent"/>
<requiresConcept refId="structure:EfferentCouplingOfComponent"/>
<description>Set a new `instability` property for each SubComponent with the range [0, 1].
instability=0 indicates a maximally stable SubComponent.
That means no type in this SubComponent has a dependency on any other type in another SubComponent of the same Component.
instability=1 indicates a maximally unstable SubComponent.
That means no type in this SubComponent is depended by any other type in another SubComponent of the same Component.
</description>
<cypher><![CDATA[
MATCH
(component:Component)-[:CONTAINS]->(subComponent:SubComponent)
WHERE
subComponent.ce + subComponent.ca > 0
WITH
component, subComponent, toFloat(subComponent.ce) / (subComponent.ce + subComponent.ca) AS instability
SET
subComponent.instability = round(instability, 2)
RETURN
component.name AS Component, subComponent.name AS SubComponent, subComponent.instability AS Instability
ORDER BY
Component DESC, SubComponent DESC
]]></cypher>
</concept>
Hier die entsprechende Ausgabe in der Dokumentation:
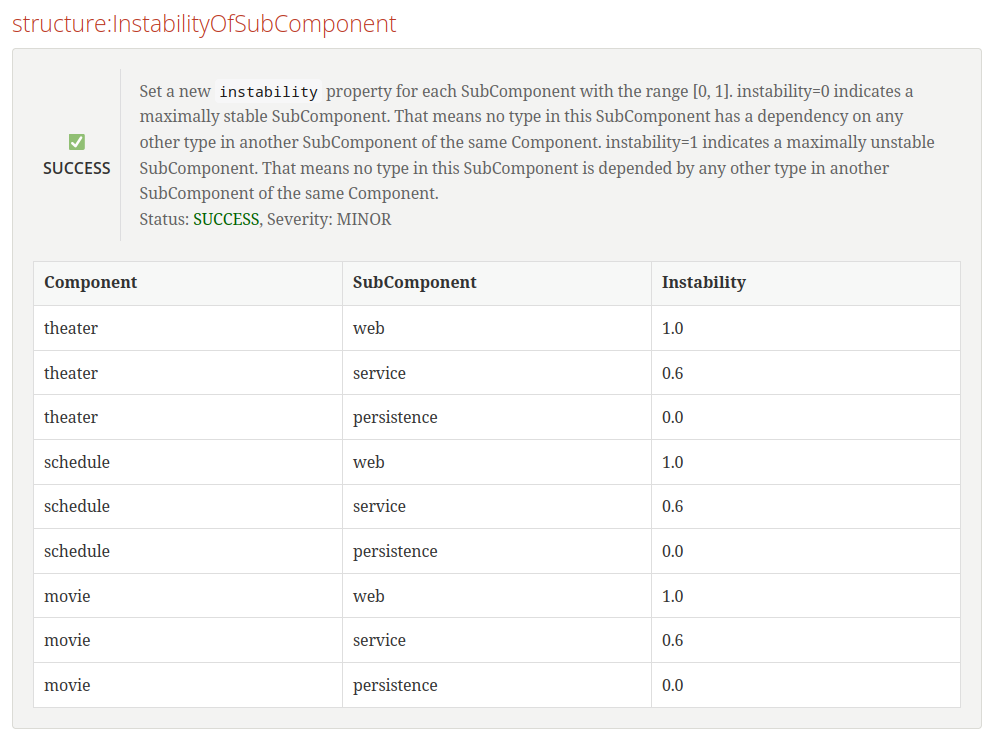
Da wir nun das Maß der Instabilität unserer Subkomponenten ermittelt haben, definieren wir nun eine neue constraint-Regel, die sicherstellt, dass eine stabile Subkomponente nicht von einer instabilen Subkomponente abhängt.
<constraint id="structure:StableSubComponentDependencies">
<requiresConcept refId="structure:ComponentDependencies"/>
<requiresConcept refId="structure:InstabilityOfComponent"/>
<description>A stable SubComponent must not depend on an unstable SubComponent inside the same Component</description>
<cypher><![CDATA[
MATCH
(c:Component)-[:CONTAINS]->(subComponent1:SubComponent)-[:DEPENDS_ON]->(subComponent2:SubComponent)<-[:CONTAINS]-(c)
WHERE
subComponent1.instability < subComponent2.instability
RETURN
subComponent1.name AS SubComponent, subComponent1.instability AS SubComponentInstability, subComponent2.name AS Dependency, subComponent2.instability AS DependencyInstability, round(subComponent2.instability - subComponent1.instability,2) AS Difference
ORDER BY
Difference DESC
]]></cypher>
</constraint>
Die oben gezeigten Regeln stellen sicher, dass das „Stable Dependencies Principle“ zwischen allen Subkomponenten unserer Anwendung eingehalten wird. Die Regeln können jedoch auch mit wenig Aufwand auf andere Ebenen der Anwendung angepasst werden. Im GitHub-Repository zu diesem Blog sind auch die entsprechenden Regeln für die Berechnung der Instabilität und die Validierung der Abhängigkeiten zwischen den Komponenten enthalten.
Zirkuläre Abhängigkeiten zwischen Komponenten
Die Abhängigkeiten zwischen den Komponenten einer Anwendung sollten einen gerichteten, azyklischen Graphen bilden. Zirkuläre Abhängigkeiten zwischen den Komponenten können zu einer unübersichtlichen Struktur führen und die Wartbarkeit der Anwendung erschweren.
Mit der folgenden Constraint-Regel können wir sicherstellen, dass es keine zirkulären Abhängigkeiten zwischen den Komponenten gibt.
<constraint id="structure:CyclicComponentDependencies">
<requiresConcept refId="structure:ComponentDependencies"/>
<description>There must be no cyclic dependencies between components</description>
<cypher><![CDATA[
MATCH
cycle = (component:Component)-[:DEPENDS_ON*]->(component)
WHERE
ALL(relation IN relationships(cycle) WHERE 'Component' IN LABELS(startNode(relation)) AND 'Component' IN LABELS(endNode(relation)))
RETURN
component.fqn AS Component, [node IN nodes(cycle) | node.fqn] AS Cycle
ORDER BY
length(cycle) DESC
]]></cypher>
</constraint>
Die MATCH-Clause sucht alle Pfade, in denen eine Komponente über beliebig viele :DEPENDS_ON-Beziehungen wieder auf sich selbst verweist. Da eine DEPENDS_ON-Beziehung aber nicht nur zwischen Komponenten, sondern zwischen allen Packages und Typen bestehen kann, müssen wir in der WHERE-Clause sicherstellen, dass nur Beziehungen zwischen Komponenten betrachtet werden. Dies erreichen wir, indem wir prüfen, ob die Start- und Endknoten jeder, der Beziehung das Label Component besitzen. Am Ende geben wir die Full Qualified Names aller Komponenten aus einem Zyklus zurück.
Diese Regel kann auch auf andere Ebenen der Anwendung angewendet werden, um zirkuläre Abhängigkeiten zu entdecken.
Zirkuläre Abhängigkeiten zwischen Typen
Ein weiteres Beispiel sind zirkuläre Abhängigkeiten zwischen Typen. Diese sind jedoch nicht unbedingt schlecht, und bei manchen Strukturen wie zum Beispiel doppelt verketteten Listen sogar gewollt. Dennoch sollten sie bewusst eingesetzt werden. Deswegen erzeugen wir im Folgenden eine Concept-Regel, die alle Typen ermittelt, die zyklische Abhängigkeiten auf sich selbst haben.
<concept id="structure:CyclicTypeDependencies">
<description>Cyclic dependencies between Types</description>
<cypher><![CDATA[
OPTIONAL MATCH
cycle = (type:Type)-[:DEPENDS_ON*]->(type)
RETURN
type.fqn AS Type, [node IN nodes(cycle) | node.fqn] AS Cycle
ORDER BY
length(cycle) DESC
]]></cypher>
</concept>
Die OPTIONAL MATCH-Anweisung unterbindet eine Warnung, falls kein Zyklus gefunden wird.
Ideen für weitere Regeln
Wer bis hier hin durchgehalten hat, kann die Konzepte aus dem letzten Blog-Artikel mit den neuen Regeln aus diesem Blog-Artikel kombinieren und so eine umfassende Strukturanalyse seiner Anwendung durchführen. Da dieser Artikel schon lang genug ist, werde ich hier nur ein paar Ideen für weiterführende Regeln geben, die Implementierung überlasse ich dann euch. 🙂
- Testabdeckung pro Komponente: Im letzten Teil der Blogreihe haben wir die Testabdeckung unserer Anwendung analysiert. Mit der Erfassung der einzelnen Komponenten könnten wir die Testabdankung auch für Teile der Anwendung ermitteln.
- Umfang der Komponenten: Neben der Testabdeckung, könnten wir auch weitere Kriterien auf Komponentenbasis erfassen. Durch die Ermittlung von Metriken wie Zeilenanzahl, Anzahl der Klassen oder Zyklomatische Komplexität könnten wir uns einen Überblick über den Umfang unserer Komponenten verschaffen.
- Hauptverantwortlicher für Komponenten: Durch die Verbindung der Typen mit den Dateien aus der Git-Historie aus dem letzten Blog kann der Haupt-Autor aller Commits ermittelt werden, die Typen in einer Komponente betreffen. Auch wenn der Code im Sinn der „Collective Ownership“ dem ganzen Team gehört und es keine spezifischen Verantwortungen geben sollte, kann es interessant sein, sich einen solchen Überblick zu verschaffen, um eventuelle Wissensinseln zu identifizieren.
- Zeitliche Abhängigkeiten: Durch die Verbindung mit den Commits aus der Git-Historie könnte man Java-Typen finden, die oft in denselben Commits geändert wurden, aber in keiner direkten Abhängigkeit zueinander stehen. Welche Aussage sich als dem Ergebnis dieser Analyse ableiten lassen könnte, ist mir zwar bis jetzt nicht klar, es könnte aber interessant sein.
Generell gilt, dass wir mit jQAssistant und den vielen Plug-ins eine riesige Datenmenge über unsere Anwendung in der Neo4j Datenbank zur Verfügung haben. Hieraus können sich die interessantesten Erkenntnisse ableiten lassen, man muss nur die richtigen Fragen stellen.
Quellen
[1] Martin, R. C. (2017). Clean Architecture: A craftsman’s guide to software structure and design.