

Alex & Hannes
CAN Analyse eines Umrichters
Umrichter sind in der Motorenansteuerung unverzichtbar. Unsere Software interagiert häufig mit Umrichtern in Produkten oder den entsprechenden Prüfständen. Die Analyse der Kommunikation zwischen Steuerung und Umrichter wird dabei unverzichtbar, um Problemen auf die Schliche zu kommen oder die Ansteuerung zu optimieren. In diesem Artikel beschreiben wir, wie wir ein Tool entwickeln das bei einer Analyse unterstützen kann.
Die Herausforderung
Die Ansteuerung eines Umrichters ist sehr projektspezifisch. Je nach Einsatzzweck unterscheidet sich die Ansteuerung, z. B. ob zu einer bestimmten Position oder mit einem bestimmten Moment in eine Richtung gefahren werden soll, oder ob sich etwas drehen oder linear bewegen soll. Die Auswertung der kommunizierten Daten wird schnell unverzichtbar, allerdings oft auch aufwendig und abhängig von den Werkzeugen der Umrichter-Hersteller.
In diesem Artikel stellen wir eine Vorgehensweise vor, wie wir eine solche Analyse mit frei verfügbaren Mitteln durchführen und eine CSV-Datei erstellen. Dafür werden wir die Kommunikation des CAN-Bus aufzeichnen, ein Programm namens “candump2csv” in Rust erstellen und die Aufzeichnung damit in eine CSV-Datei transformieren. Diese CSV-Datei kann dann z. B. in Excel oder LibreOffice Calc zur Visualisierung geöffnet werden.
Die Ausgangssituation
In unserem Beispiel ist der Umrichter per CAN angeschlossen und unterstützt DS402. DS402 definiert mit Hilfe der Referenzprofils CiA 402 ein standardisiertes Protokoll für Antriebe bzw. “Bewegungssteuerungen” (aus dem Englischen “drives and motion controller devices”) und ist Teil der Norm IEC 61800-7. Auch wenn die Norm nicht kostenlos zur Verfügung steht können die benötigten Informationen und CAN Nachrichten, wenn ein Umrichter diesen Standard unterstützt, aus dem Umrichter-Handbuch entnommen werden.
Achtung: Hierbei gibt es unterschiedliche Ausprägungen, ein Blick in das Handbuch ist unersetzlich! Für diesen Blog-Artikel haben wir “standardisierte” Nachrichten verwenden, das Vorgehen kann aber auf sämtliche Nachrichten angewendet werden.
Das Gerät auf dem unsere Steuerungssoftware läuft bietet eine Debian-basierte Linux-Umgebung. Prinzipiell kann die Analyse aber mit jedem Gerät durchgeführt werden auf dem eine Linux-Distribution installiert ist, das eine CAN-Schnittstelle besitzt und an den CAN-Bus des zu analysierenden Umrichters angeschlossen ist.
Aufzeichnen der Kommunikation
Um die gesamte CAN-Kommunikation aufzuzeichnen verwenden wir das Tool candump.
candump ist Teil der CAN-Tool-Sammlung can-utils (siehe Github-Repository
) und kann in den meisten Distributionen mit Hilfe des jeweiligen Paketmanagers installiert werden.
In unserem Fall mit sudo apt install can-utils.
Nachdem das Paket installiert wurde steht candump als Anwendung zur Verfügung.
1❯ candump
2
3candump - dump CAN bus traffic.
4
5Usage: candump [options] <CAN interface>+
6 (use CTRL-C to terminate candump)
7
8...
Nun können wir eine candump-Log-Datei erstellen.
Hier können wir schon nach bestimmten CAN-IDs filtern.
Dies ist wichtig, wenn wirklich sehr viele Daten über den Bus verschickt werden.
In diesem Beispiel werden wir zunächst alle CAN-Frames aufzeichnen und in die Log-Datei schreiben und diese später filtern.
Die Aufzeichnung kann nun mit candump can0 -l candump.log gestartet und mit Ctrl+c wieder gestoppt werden.
Dies produziert die Datei candump.log im aktuellen Verzeichnis.
In der Datei stehen nun sämtliche CAN-Frames die während der Aufzeichnung empfangen wurden.
1❯ cat candump.log
2(1687118029.546454) can0 281#58650C01FFFFFFFF
3(1687118029.551903) can0 284#18FEFFFF09000000
4(1687118029.553082) can0 282#AD650C01FFFFFFFF
5(1687118029.556431) can0 281#5A650C01FFFFFFFF
6(1687118029.561903) can0 284#18FEFFFF0A000000
7(1687118029.563086) can0 282#AD650C0100000000
8(1687118029.566420) can0 281#5B650C01FFFFFFFF
9(1687118029.571897) can0 284#18FEFFFF1B000000
10(1687118029.573089) can0 282#AD650C0100000000
11(1687118029.576425) can0 281#5B650C01FFFFFFFF
12(1687118029.581899) can0 284#18FEFFFF59000000
13(1687118029.583082) can0 282#AD650C01FFFFFFFF
14(1687118029.586426) can0 281#5A650C01FFFFFFFF
15(1687118029.591895) can0 284#18FEFFFFE8FFFFFF
16(1687118029.593088) can0 282#AD650C0100000000
17(1687118029.596429) can0 281#59650C0100000000
18(1687118029.601906) can0 284#18FEFFFFFAFFFFFF
19(1687118029.603080) can0 282#AD650C0100000000
20(1687118029.606415) can0 281#59650C0100000000
21(1687118029.611901) can0 284#18FEFFFF15000000
22(1687118029.613075) can0 282#AD650C01FFFFFFFF
23(1687118029.616415) can0 281#59650C01FFFFFFFF
24(1687118029.621895) can0 284#18FEFFFFE8FFFFFF
25(1687118029.623075) can0 282#AD650C01FFFFFFFF
26(1687118029.626419) can0 281#58650C0100000000
27(1687118029.631898) can0 284#18FEFFFF0B000000
28(1687118029.633074) can0 282#AD650C01FFFFFFFF
29(1687118029.636156) can0 701#05
30(1687118029.636670) can0 281#5B650C0100000000
31(1687118029.637860) can0 000#8102
32(1687118029.638821) can0 702#00
33
34// ...
Diese Datei verwenden wir im nächsten Schritt zur Erstellung einer CSV-Datei.
Konfigurieren der Auswertung
Im nächsten Schritt müssen wir festlegen was genau wir analysieren wollen.
Zunächst einmal hat unser Umrichter die NodeId 4 in unserem Aufbau.
Das ist wichtig zur Bestimmung der CANopen-Identifier der Nachrichten.
Die NodeId des Absenders ist dabei die letzte Ziffer des Identifiers.
In unserem Beispiel untersuchen wir bei welchem Positionswert der Umrichter meldet, dass er beim angegebenen Ziel angekommen ist.
Info: Die Position steht im “Object 6064h: Position Action Value” nach DS402-Standard. Dieses Objekt wird verwendet, wenn der Umrichter, wie in unserem Fall, im “Position Profile” betrieben wird. Das Mapping in das PDO ist anwendungsspezifisch und muss im Umrichter selbst, oder bei der Initialisierung der Kommunikation konfiguriert werden.
Der Positionswert steht in unserem Beispiel in einem PDO (einem zyklisch geschickten CAN-Frame) mit dem Identifier 0x284.
Info: Die Position steht im “Object 6064h: Position Action Value” nach DS402-Standard.
In diesen CAN-Nachrichten steht die Positionsinformation als Ganzzahl in den niederwertigsten 4-Bytes, also als 32bit-Integer (int32) da so in unserem PDO konfiguriert.
Dass der Umrichter an seinem Ziel angekommen ist, wird mit dem Flag Target Reached signalisiert.
Info: Dieses Flag ist im Standard DS402 im “Object 6041h”, dem “status word” standardisiert.
Auch dies bekommen wir in einem PDO, mit dem Identifier 0x184, zugeschickt.
Die Information Target Reached ist dabei ein Boolean, also wahr oder falsch, und steht im zweiten Byte an Position 3.
Um diese Information aus dem CAN-Frame zu extrahieren, wenden wir eine Maske mit dem Wert 0x400 auf den Inhalt des CAN-Frames an.
Dies bedeutet: “Es ist nur das 3. Bit im 2. Byte interessant”.
Zusammenfassend stellen wir fest: Wir benötigen für jede Information die uns interessiert einen Namen (z. B. “Position” oder “Target Reached”), einen Identifier des CAN-Frames (z. B. “0x284” oder “0x184”), eine Maske zur Extraktion (z. B. “0xFFFFFFFF” oder “0x400”) und einen Typ (z. B. “int32” oder “bool”). Für unsere candump2csv-Software wollen wir dies in einer JSON-Datei konfigurieren.
1[
2 {
3 "header": "Target Reached",
4 "id": "0x184",
5 "bitmask": "0x400",
6 "column_type": "bool"
7 },
8 {
9 "header": "Position",
10 "id": "0x284",
11 "bitmask": "0xFFFFFFFF",
12 "column_type": "int32"
13 }
14]
15
Rust-Projekt erstellen
Info: Wir haben den vollständigen Quellcode auch in einem GitHub-Repository bereitgestellt. Das Repository findest du unter https://github.com/uxitra/candump2csv .
Um ein neues Rust-Projekt zu erstellen wird ein Rust-Compiler benötigt. Wir setzen die Installation an dieser Stelle voraus, die offizielle Dokumentation ist an dieser Stelle sehr ausführlich.
cargo new candump2csv erstellt ein neues Rust-Projekt namens “candump2csv”.
Zuerst fügen wir clap als Abhängigkeit hinzu.
clap bietet uns eine einfache Möglichkeit die CLI-Schnittstelle zu definieren, denn wir benötigen die folgenden Informationen in unserem Programm:
- Den Pfad zur Konfigurationsdatei
- Den Pfad zu unserer candump-Log-Datei
- Den Pfad zu unserer gewünschten Ausgabedatei
Um clap hinzuzufügen passen wir die Datei Cargo.toml entsprechend an:
1[dependencies]
2clap = { version = "4.0", features = ["derive"] }
Damit können wir nun in der Datei src/main.rs ein struct für die CLI-Optionen anlegen und dieses in der main-Methode verwenden.
1use clap::Parser as CliParser;
2use std::{path::PathBuf, process::ExitCode};
3
4#[derive(CliParser, Debug)]
5#[command(version, about, long_about = None)]
6#[clap(
7 version,
8 about = "A command line tool to parse a log file of candump into a CSV only extracting the CAN ids and signals/values specified in a config file."
9)]
10struct Cli {
11 #[arg(long)]
12 config_file: PathBuf,
13 #[arg(long)]
14 candump_file: PathBuf,
15 #[arg(short, long)]
16 output_file: PathBuf,
17}
18
19fn main() -> ExitCode {
20 let args = Cli::parse();
21
22 ExitCode::SUCCESS
23}
Die Konfiguration einlesen
Um unsere Konfiguration im JSON-Format zu lesen verwenden wir die folgenden Abhängigkeiten:
- serde : Bietet Unterstützung für die Serialisierung und Deserialisierung unterschiedlichster Dateiformate
- serde_json : Stellt die JSON-spezifische Implementierung für serde bereit.
- serde-hex : Wird zur Deserialisierung von hexadezimalen Werten verwenden.
Um die Bibliotheken unserem Projekt hinzuzufügen, passen wir die Datei Cargo.toml entsprechend an:
1[dependencies]
2...
3serde = { version = "1.0.218", features = ["derive"] }
4serde_json = "1.0.139"
5serde-hex = { git = "https://github.com/thomaseizinger/serde-hex", branch = "support-deserialize-owned-strings"}
Exkurs: Wer aufmerksam die Änderungen an der Datei
Cargo.tomlverfolgt, dem fällt auf dass wir an dieser Stelle einen Fork des serde-hex-Repositories eingebunden haben. Grund dafür ist ein Bug, durch diesen es nicht möglich ist hexadezimale Werte innerhalb einer Liste zu (de-)serialisieren. Das eingebundene Repository bietet hierfür einen Fix und es wurde ein Pull-Request im ursprünglichen Repository eröffnet. Zum Zeitpunkt der Erstellung unserer Auswertesoftware wurde dieser Pull-Request leider noch nicht wieder in das ursprüngliche Repository integriert.
Um unsere Konfiguration, im Folgenden Definitions genannt, im Code zu verwenden legen wir structs als Datenmodell und eine Methode für das Einlesen in der Datei src/main.rs an.
Die entsprechenden use müssen hinzugefügt werden.
Der einfachste Weg ist die entsprechenden Zeilen aus der Datei in unserem Repository zu kopieren, oder diese sich durch die Entwicklungsumgebung oder den Editor automatisch einfügen zu lassen.
1#[derive(Debug, PartialEq, Eq, Serialize, Deserialize)]
2enum ColumnType {
3 #[serde(rename = "bool")]
4 Bool,
5 #[serde(rename = "uint32")]
6 UInt32,
7 #[serde(rename = "int32")]
8 Int32,
9 #[serde(rename = "int16")]
10 Int16,
11 #[serde(rename = "int8")]
12 Int8,
13}
14
15#[derive(Debug, PartialEq, Eq, Serialize, Deserialize)]
16struct ColumnDefinition {
17 header: String,
18 #[serde(with = "SerHex::<CompactPfx>")]
19 id: u32,
20 #[serde(with = "SerHex::<CompactPfx>")]
21 bitmask: u64,
22 column_type: ColumnType,
23}
24
25#[derive(Debug, Serialize, Deserialize)]
26#[serde(transparent)]
27struct Definition {
28 column_definitions: Vec<ColumnDefinition>,
29}
30
31fn read_defs_from_file<P: AsRef<Path>>(path: P) -> Result<Definition, Box<dyn Error>> {
32 // Open the file in read-only mode with buffer.
33 let file = File::open(path)?;
34 let reader = BufReader::new(file);
35
36 let def = serde_json::from_reader(reader)?;
37
38 // Return the `Definitions`.
39 Ok(def)
40}
Einlesen der Aufzeichnung
Nun zur eigentlichen Logik des Auswertetools.
In unserer Aufzeichnung entspricht eine Zeile einem CAN-Frame.
Das Format ist spezifisch für candump.
Nach einer kurzen Recherche wurde dieses Problem auch schon gelöst, und zwar in der candump-parse-Bibliothek (auch genannt crate im Rust-Ökosystem).
So müssen wir wieder unsere Cargo.toml anpassen.
1[dependencies]
2...
3candump-parse = "0.1.0"
4chumsky = { version = "0.9.*", default-features = false }
chumsky ist dabei eine Abhängigkeit der candump-parse und unterstützt bei der Erstellung von hoch performanten Parsern.
Jetzt fehlt nur noch der Aufruf in unserer main-Methode.
Dabei müssen wir jede Zeile unserer Log-Datei in den Parser geben.
Das Ergebnis des Parser-Aufrufs ist eine Instanz des in der candump-parse mitgelieferten struct CandumpFrame.
1fn main() -> ExitCode {
2
3 //...
4
5 let can_frames = match read_lines(args.candump_file) {
6 Ok(lines) => lines
7 .map_while(Result::ok)
8 .map_while(|line| parser().parse(line).ok())
9 .collect::<Vec<_>>(),
10 Err(e) => {
11 println!("Cannot open or parse candump file. Aborting. {e}");
12 return ExitCode::FAILURE;
13 }
14 };
15
16 ExitCode::SUCCESS
17}
Die Extraktion der Informationen
Nun können die Informationen aus den einzelnen CAN-Frames extrahiert werden.
Dazu legen wir die Methode extract_bits an.
1fn extract_bits(bitmask: u64, data: &[u8]) -> u64 {
2 let mut result = 0;
3 let mut bit_position = 0;
4
5 for i in 0..64 {
6 if (bitmask & (1 << i)) != 0 {
7 let byte_index = i / 8;
8 let bit_index = i % 8;
9
10 if byte_index < data.len() {
11 let bit = (data[byte_index] >> bit_index) & 1;
12 result |= (bit as u64) << bit_position;
13 }
14 bit_position += 1;
15 }
16 }
17
18 result
19}
Hierbei werden die konfigurierten Bitmasken auf die tatsächlichen Bytes im eingelesenen CanFrame angewendet.
Der CanFrame wird dabei als Array von Bytes (u8 = “unsigned 8-bit Integer”) in die Methode übergeben.
Das Schreiben der CSV-Datei
Nun können alle Einzelteile zusammengebaut werden, um die gewünschten Informationen im gewünschten Format in die Ausgabe-Datei zu schreiben.
Da die Methode etwas länger wird, werden die Code-Beispiele aufgeteilt.
Zunächst einmal muss eine neue Datei angelegt und geöffnet werden.
1fn write_output_file(
2 output_file: &Path,
3 definition: Definition,
4 can_frames: &[CandumpFrame],
5) -> io::Result<()> {
6 let file = File::create(output_file)?;
7 let mut writer = LineWriter::new(file);
8
9 let start_timestamp = can_frames.first().unwrap().timestamp;
10
11 let mut column_values = HashMap::<&str, u64>::new();
12
13 //Write headers
14 write!(writer, "Timestamp[ms]")?;
15 for column in &definition.column_definitions {
16 column_values.insert(&column.header, 0);
17 write!(writer, ",{}", column.header)?;
18 }
19 writeln!(writer)?;
20
21 Ok(())
22}
Für die Ausgabe benötigen wir den Startzeitstempel der Aufnahme.
Diesen bekommen wir aus dem ersten CanFrame.
Danach werden direkt die Überschriften der CSV-Datei (die erste Zeile) mit der Konfiguration (genannt definition) geschrieben.
Als Trennzeichen (auch “delimiter”) wird ganz klassisch ein ‘,’ verwendet.
Als nächsten müssen alle CanFrames in der Liste angeschaut werden, ob in diesem Informationen stecken, die wir in die CSV-Datei schreiben wollen. Dazu verwenden wir eine “for each”-Schleife.
1fn write_output_file(
2 output_file: &Path,
3 definition: Definition,
4 can_frames: &[CandumpFrame],
5) -> io::Result<()> {
6
7 //...
8
9 for can_frame in can_frames {
10 // find the corresponding columns for the can frame id, we might have multiple columns for the same id
11 let matching_ids = definition
12 .column_definitions
13 .iter()
14 .filter(|column| column.id == can_frame.id);
15 }
16
17 Ok(())
18 }
Nachdem wir festgestellt haben, dass in dem aktuellen CanFrame Informationen enthalten sind die wir benötigen, müssen die Informationen noch extrahiert werden. Achtung: Dabei kann es vorkommen, dass unterschiedliche Informationen, also für unterschiedliche Spalten in der CSV-Datei im gleichen CanFrame enthalten sind.
1fn write_output_file(
2 output_file: &Path,
3 definition: Definition,
4 can_frames: &[CandumpFrame],
5) -> io::Result<()> {
6
7 // ...
8
9 for can_frame in can_frames {
10 // find the corresponding columns for the can frame id, we might have multiple columns for the same id
11 let matching_ids = definition
12 .column_definitions
13 .iter()
14 .filter(|column| column.id == can_frame.id);
15
16 // flag to mark that we found at least one matching filter
17 let mut found = false;
18
19 for column in matching_ids {
20 // update the entry for the new value of the column
21 column_values.insert(
22 &column.header,
23 extract_bits(column.bitmask, &can_frame.data),
24 );
25 found = true;
26 }
27 }
28
29 Ok(())
30}
Bis hierher werden die column_values befüllt, damit jede Zeile in der CSV-Datei auch den letzten empfangenen Wert aller Spalten beinhaltet.
Als Abschluss müssen die Informationen noch tatsächlich in die geöffnete Datei geschrieben werden.
1fn write_output_file(
2 output_file: &Path,
3 definition: Definition,
4 can_frames: &[CandumpFrame],
5) -> io::Result<()> {
6
7 // ...
8
9 for can_frame in can_frames {
10
11 // ...
12
13 if found {
14 // Write timestamp in ms
15 write!(
16 writer,
17 "{:?}",
18 (can_frame.timestamp - start_timestamp).as_millis()
19 )?;
20 for column in &definition.column_definitions {
21 let value = column_values.get(column.header.as_str()).unwrap();
22 let column_type = &column.column_type;
23 match column_type {
24 ColumnType::Bool => write!(writer, ",{value}")?,
25 ColumnType::Int32 => write!(writer, ",{}", *value as i32)?,
26 ColumnType::Int16 => write!(writer, ",{}", *value as i16)?,
27 ColumnType::Int8 => write!(writer, ",{}", *value as i8)?,
28 ColumnType::UInt32 => write!(writer, ",{}", value)?,
29 }
30 }
31 writeln!(writer)?;
32 }
33 }
34
35 Ok(())
36}
Zu guter Letzt muss die main-Methode noch um den Aufruf der write_output_file-Methode ergänzt werden, dann ist das CAN-Dump-Transformations-Werkzeug schon fertig.
1fn main() -> ExitCode {
2
3 // ...
4
5 if can_frames.is_empty() {
6 println!("No frames found in candump file. Aborting");
7 return ExitCode::FAILURE;
8 }
9
10 match write_output_file(&args.output_file, defs, &can_frames) {
11 Ok(()) => ExitCode::SUCCESS,
12 Err(e) => {
13 println!("Failed to write to output file. {e}");
14 ExitCode::FAILURE
15 }
16 }
17}
Compilieren
Damit wir unsere Analyse-Software ausführen können, müssen wir diese noch compilieren.
Dazu können wir einen Release-Build mit cargo build --release erstellen.
Bei erfolgreichem Build wird unter “target/release” das ausführbare Programm candump2csv abgelegt.
Es kann demnach mit ./target/release/candump2csv ausgeführt werden, es wird dabei eine Nachricht zur richtigen Benutzung angezeigt.
Diese wird mit Hilfe der crate clap in unseren Abhängigkeiten automatisch erstellt.
Das Ergebnis
Als Abschluss des Blog-Artikels werden wir eine Aufzeichnung eines Umrichters mit Hilfe unseres Programms umwandeln um in Microsoft Excel ein Chart zur Visualisierung zu erstellen.
Hierfür haben wir mit candump eine Sequenz aufgezeichnet.
Hier ein kleiner Ausschnitt aus der example.log-Datei:
1// ...
2
3(1687118574.917166) can0 282#5AC8010000000000
4(1687118574.920022) can0 281#0DC80100FFFFFFFF
5(1687118574.921376) can0 284#7646FFFF1F000000
6(1687118574.921875) can0 283#7CC8010000000000
7(1687118574.927170) can0 282#5AC80100FFFFFFFF
8(1687118574.930039) can0 281#0DC8010000000000
9(1687118574.931392) can0 284#7646FFFF0C000000
10(1687118574.931869) can0 283#7CC8010000000000
11(1687118574.937179) can0 282#5AC80100FFFFFFFF
12(1687118574.940023) can0 281#0DC80100FFFFFFFF
13
14// ...
Für die Umwandlung in eine .csv-Datei benötigen wir noch eine Konfigurationsdatei.
1[
2 {
3 "header": "Target Reached",
4 "id": "0x181",
5 "bitmask": "0x400",
6 "column_type": "bool"
7 },
8 {
9 "header": "Acknowledge",
10 "id": "0x181",
11 "bitmask": "0x1000",
12 "column_type": "bool"
13 },
14 {
15 "header": "Position",
16 "id": "0x281",
17 "bitmask": "0xFFFFFFFF",
18 "column_type": "int32"
19 }
20]
In dieser Analyse wollen wir das Zeitverhalten untersuchen. Uns interessiert:
- Wie lange benötigt der Umrichter, um die Bewegung tatsächlich zu starten?
- technisch: Wann beginnt sich die Posiotion zu verändern nachdem das Flag Acknowledge auf HIGH gesetzt wurde?
- Wie lange dauert es, bis der Umrichter nach erreichen der Zielposition den Bewegungsvorgang abschließt?
- Wann wird das Flag Target Reached auf HIGH gesetzt?
Mit diesen Daten können wir nun unser Transformationsprogramm ausführen: ./target/release/candump2csv --config-file config.json --candump-file example.log --output-file example.csv.
Zum Abschluss noch ein Screenshot des Ergebnisses in Excel:
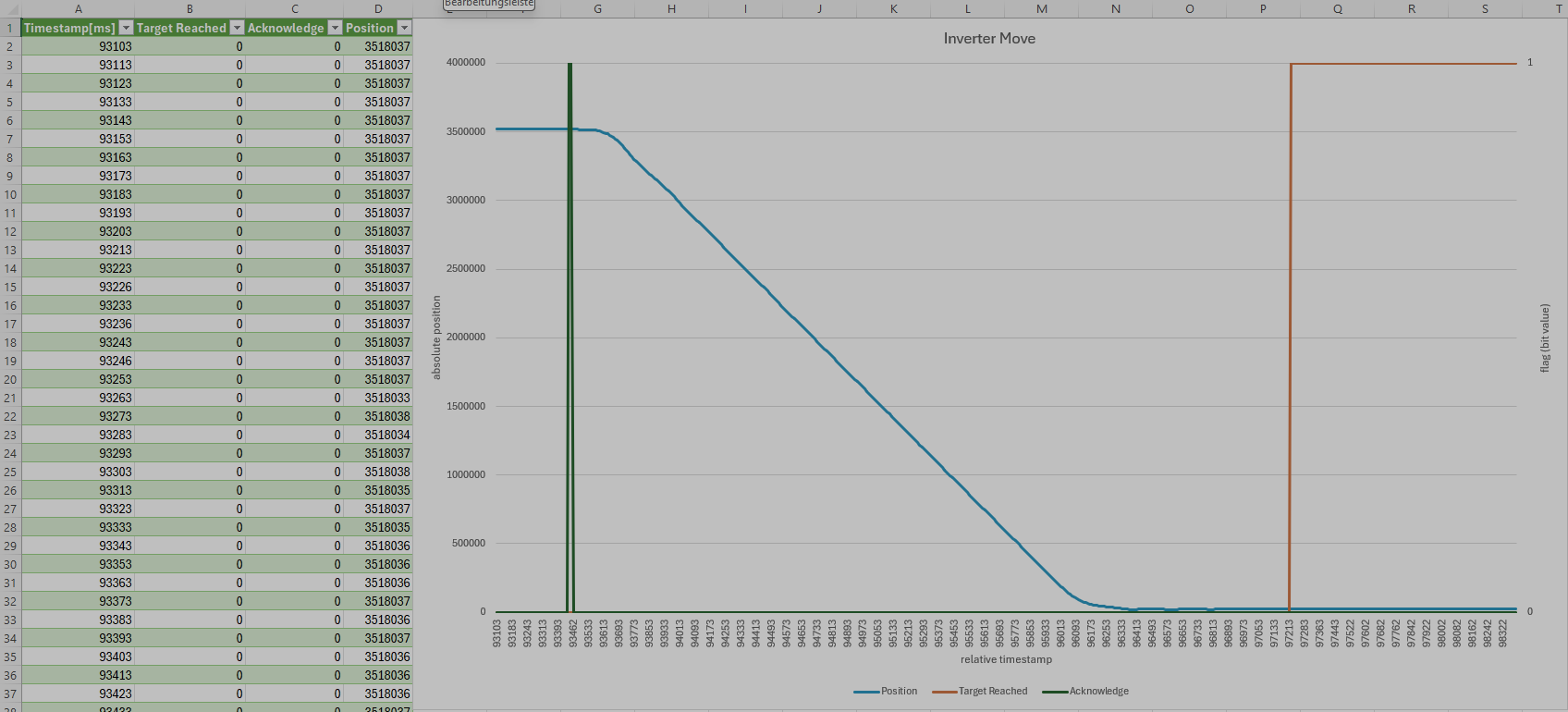
Viel Erfolg und Happy Coding!
Vollständiges Projekt auf GitHub unter https://github.com/uxitra/candump2csv .